
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- HTML
- 날씨 웹 만들기
- 자바스크립트 날씨
- RN 프로젝트
- [파이썬 실습] 심화 문제
- [파이썬 실습] 기초 문제
- [AI 5기] 연습 문제집
- 코드스테이츠
- [파이썬 실습] 중급 문제
- 코딩부트캠프
- 자바스크립트 날씨 웹 만들기
- 프론트개발공부
- 부트캠프
- reactnativecli
- 엘리스 AI 트랙 5기
- 자바스크립트 split()
- 개발일기
- 리트코드
- 자바스크립트 reduce()
- 프론트개발
- 자바스크립트
- 엘리스 ai 트랙
- 프로그래머스
- 간단한 날씨 웹 만들기
- 삼항연산자
- 개발공부
- leetcode
- 자바스크립트 sort()
- JavaScript
- 엘리스
- Today
- Total
개발조각
[프로그래머스] [3차] 압축 본문
프로그래머스 2단계에서 [3차]~~ 이런 문제들이 몇 개 있는데
이번 문제는 [3차] 문제 중에서 쉬운 편에 속한 것 같아요.
그러나 저는 for문에 break를 안걸어서 몇 시간 동안 헤매고 풀었습니다.(진짜 바보다ㅋㅋㅋ)

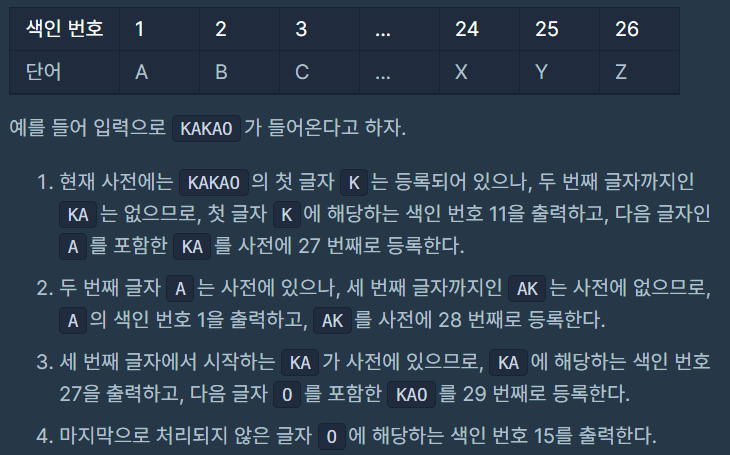
문제 설명이 길어서 여기까지만 붙이겠습니다.
접근방법
이번 문제는 규칙성만 잘 파악하시면 쉽게 풀 수 있어요.
A~Z를 1~26으로 구성된 사전이 있습니다.
- ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
이런 순으로 구성되어 있습니다.

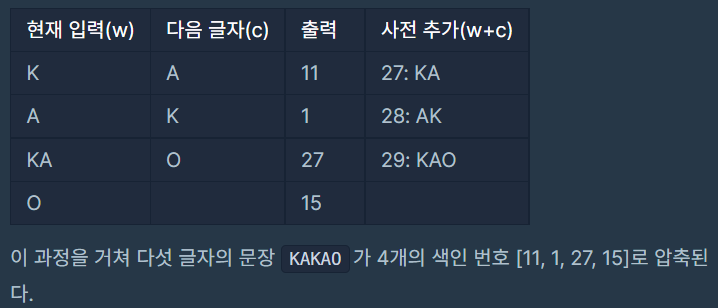
테스트1 예제 'KAKAO'를 보시면
현재 입력(w) : 'K'이면, 다음 글자(c)는 'A'입니다.
'K'를 출력하면 11이 됨으로 11을 출력하고, w+c를 사전 27번에 'KA'를 해줍니다.
그럼 사전은
- ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'KA']
이렇게 됩니다.
이 방식을 반복하다가 보면 문자열이 2개일 때 이 문자열이랑 같은 문자열이 사전에 있을 수 있습니다.
'KA'와 같은 경우 입니다.
'KA'는 사전 27번에 있습니다.
그럼 K=15, A=1 이렇게 넣는 것이 아니라 KA=27을 출력하면 됩니다.
그래서 저는 어떻게 풀었다면
- 사전에서 문자열 길이가 가장 긴 문자열 길이 값을 찾고
-> 사전에 가장 긴 문자열 길이 : 3 - 현재 입력될 위치부터 사전에 가장 긴 문자열 길이만큼 문자열이 사전에 있는지 확인합니다.
-> 현재 위치부터 ~+3까지의 문자열 반환 - 사전에 없으면 사전에 가장 긴 문자열 길이-1이 사전에 있는지 확인합니다.(있을 때까지 확인합니다.)
-> 현재 위치부터 ~+2까지의 문자열 반환 - 사전에 있으면 출력 값을 찾아주면 됩니다.
이 과정을 msg문자열이 끝날 때까지 반복하면 됩니다.
결론은 현재 입력(w)의 값을 최대한 길 때의 값을 return 해주는 문제입니다.
해결방안
function solution(msg) {
let dictionary = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S','T', 'U', 'V', 'W', 'X', 'Y', 'Z']
var answer = [];
let i=0;
while(i<msg.length){
let strLength = dictionary.map(a=> a.length);
let maxJ = Math.max(...strLength);
for(let j= maxJ; j>0; j--){
let w = msg.substring(i, j+i);
let wNum = dictionary.indexOf(w);
if(wNum !== -1){
answer.push(wNum+1);
dictionary.push(w+msg[i+j]);
i+=j;
break;
}
}
}
return answer;
}
해결방안 순서
- A~Z까지 배열로 담아준다.
- while문으로 i=0 초기값을 설정해주고, i<msg.length일 때 동안 반복문으로 돌려준다.
- dictionary배열의 문자열 중에서 가장 긴 찾는다.
- for문으로 j=2단계 값 초기값으로 설정해주고 j>0이 될 때까지 반복해준다.
- 현재 입력(w)과 현재 입력이 사전에 어디에 위치하는지 찾는다.
- 만약 현재 입력(w)이 사전에 있다면 그 출력 값을 answer에 담아주고, w+c값을 사전에 추가해준다.
1단계. A~Z까지 배열로 담아준다.
let dictionary = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S','T', 'U', 'V', 'W', 'X', 'Y', 'Z']
var answer = [];문제 설명에서

A~Z를 이렇게 지정한다고 합니다.
그래서 저도 A~Z를 dictionary에 담아주었습니다.
(주의해야 될 점 배열을 0부터 시작하는데 문제 설명에서는 1부터 시작함으로 뒤에 코드를 쓸 때 +1을 해주어야 됩니다.)
var answer = [] : return값을 담아줄 배열
2단계. while문으로 i=0 초기값을 설정해주고, i<msg.length일 때 동안 반복문으로 돌려준다.
let i=0;
while(i<msg.length)저는 여기서 for문이 아닌 while문을 사용해 주었습니다.
while문을 사용해준 이유는
아래 예제와 같이 현재 입력(w)이 한글 자일 수도 있고 세 글자일 수도 있기 때문입니다.

3단계. dictionary배열의 문자열 중에서 가장 긴 찾는다.
let strLength = dictionary.map(a=> a.length);
let maxJ = Math.max(...strLength);4단계에서 for문을 사용할 때 j의 값을 설정해주기 위해 코드를 작성했습니다.
map()를 이용해서 dictionary배열의 문자열의 길이를 담아주고,
Math.max()를 이용해서 가장 큰 값을 반환해주었습니다.
4단계. for문으로 j=2단계 값 초기값으로 설정해주고 j>0이 될 때까지 반복해준다.
for(let j= maxJ; j>0; j--)이 for문 안에는 현재 입력(w)을 구할 코드인데요.
현재 입력(w)은 문자열 길이가 가장 긴 값으로 구해야 돼서 3단계에서 구한 maxJ의 값을 초기값으로 설정해 주었습니다.
5단계. 현재 입력(w)과 현재 입력이 사전에 어디에 위치하는지 찾는다.
let w = msg.substring(i, j+i);
let wNum = dictionary.indexOf(w);현재 입력(w)은 substring()으로 구하였습니다.
substring() 메소드는 string 객체의 시작 인덱스로부터 종료 인덱스 전까지 문자열의 부분 문자열을 반환해줍니다.
시작 인덱스에는 i를 넣어주고 종료 인덱스는 j+1을 넣어주었습니다.
// substring()메소드 예제
const str = 'Mozilla';
console.log(str.substring(1, 3));
// expected output: "oz"j+1을 넣어준 이유는 위에 예제를 보시면 이해가 되실 것 같습니다.
그리고 현재 입력(w)이 dictionary에 있는지 확인하기 위해 indexOf()메소드를 사용해 주었습니다.
w가 사전에 있으면 -1이 아닌 숫자가 나옵니다.
6단계. 만약 현재 입력(w)이 사전에 있다면 그 출력 값을 answer에 담아주고, w+c값을 사전에 추가해준다.
if(wNum !== -1){
answer.push(wNum+1);
dictionary.push(w+msg[i+j]);
i+=j;
break;
}만약 w가 사전에 있을 경우
answer에 wNum+1을 넣어줍니다.
이때 +1을 해준 이유는 문제 설명에서의 사전에는 1부터 시작인데 배열에서 0부터 시작이라 +1를 해주었습니다.
그리고 사전에 w+c를 추가해줘야 돼서 dictionary에 w+msg[i+j]를 넣어주었습니다.
msg[i+j]를 해준 이유는 w = msg.substring(i, j+i);인데 이 값의 다음 문자의 위치를 구해야 되기 때문에 i+j를 해주었습니다.
이제 while문을 쓴 이유가 여기에 나오는데요.
i+=j를 해주기 위해서입니다.
w가 'K'일 수도 있고, 'KA'일 수도 있고, 'KAB'일 수도 있습니다.
여기서 j가 단순히 w의 종료 인덱스를 찾기 위한 요소일 뿐만 아니라 w의 문자열 길이가 무엇인지도 지정해 줍니다.
이 부분이 가장 중요합니다.
w의 값은 가장 길 때를 구하는 겁니다.
가장 길었을 때를 구하면 다음 문자열을 출력해줘야 됩니다.
그러나 for문으로 설정해 주었기 때문에 break를 안 해주면 j=1이 될 때까지 반복이 됩니다.
지금까지 j=1이 아닐 때를 구하려고 한 건데 다할 필요가 없잖아요.
그리고 그대로 진행하면 j=1일 때는 무조건 존재하기 때문에 j=3일 때 j=2일 때 if문에 되었던 게 다 무효처리가 되고 j=1일 때가 들어가 됩니다.
그래서 if문을 구했으면 for문을 끝내면 됩니다. 그래서 break를 넣어주었습니다.
여기까지 프로그래머스 [3차] 압축 해결방안에 대해 설명해보았습니다.
'알고리즘🅰 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] 문자열 압축 (0) | 2022.05.02 |
|---|---|
| [프로그래머스] 스킬트리 (0) | 2022.05.02 |
| [프로그래머스] [3차] 파일명 정렬 (0) | 2022.04.28 |
| [프로그래머스] 올바른 괄호 (0) | 2022.04.27 |
| [프로그래머스] 다음 큰 숫자 (0) | 2022.04.27 |



